
Learn how to block a specific URL path from crawling and indexing by adding a meta robots tag.
If you’ve installed SEO plugins, you’ll know that you can easily control the Robots Meta Tags for specific URLs or post types. If you enable custom post types, you can set their Robots Meta directives to noindex, nofollow and others.
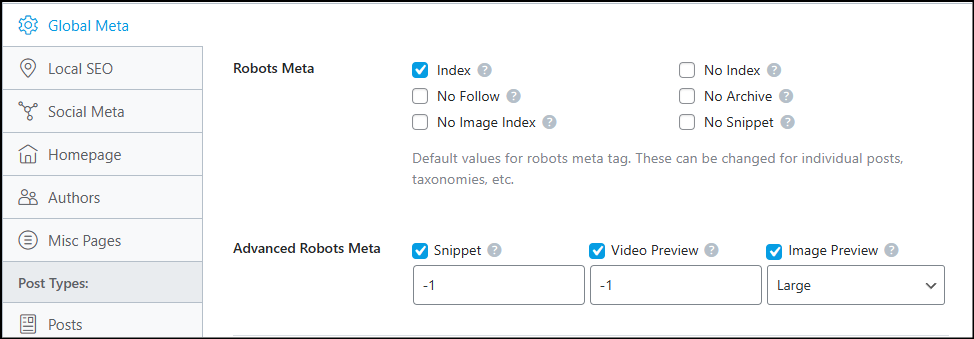
But what if you want to noindex a URL path not present in Rankmath, Yoast, AISEO or your favorite SEO plugin?
How would you noindex all URLs that are like this:
- https://example.com/page/1
- https://example.com/page/2
- https://example.com/page/3
This is a classic case of a paginated URL being indexed by search engines, and you might not want it to appear on Google or Bing searches.
Some plugins can handle this out of the box, but the problem increases if Google Search crawls and indexes different types of URL paths that do not appear in any of the plugin’s settings panel.
For example,
- https://example.com/project/list/?project-type=2&project-date-2021
- https://example.com/project/list/?project-type=3&project-date-2023
- https://example.com/project/list/?project-type=3&project-date-2024
or
- https://example.com/events/list/page/9/?tribe-bar-date=2025-05-18&eventDisplay=past
- https://example.com/events/list/page/6/?tribe-bar-date=2024-11-17&outlook-ical=1
- https://example.com/events/list/?tribe-bar-date=2020-04-28&ical=1
- https://example.com/events/list/page/6/?tribe-bar-date=2019-04-15&outlook-ical=1
When Google bots crawl these URLs, the systems might check if there is content worth indexing. If these URLs are automated to generate content for a user (such as showing a list of projects for a particular year), then they might be crawled and sometimes indexed. Furthermore, they might be treated as pages with thin content, and search engines might classify your site as unhelpful.
If you didn’t intend this, the best way to work on it is to noindex them from the search. You would instead get your main URL indexed rather than automatically generated ones. For example, you might want to index https://example.com/project/your-work rather than those mentioned above with pages 1,2,3
I’ve researched a lot and haven’t found a solution, such as a plugin, to solve this issue. So, I looked at how non-coders like me can do this quickly, and there is an easy way to handle Robots Meta for any URL path on WordPress.
How to Noindex or Block Specific URL Paths On Google Search in WordPress
We will Noindex specific URL paths in WordPress by adding the path of the URL using a simple piece of PHP code and a plugin (WPCode) to add that code.
Install & activate WPCode
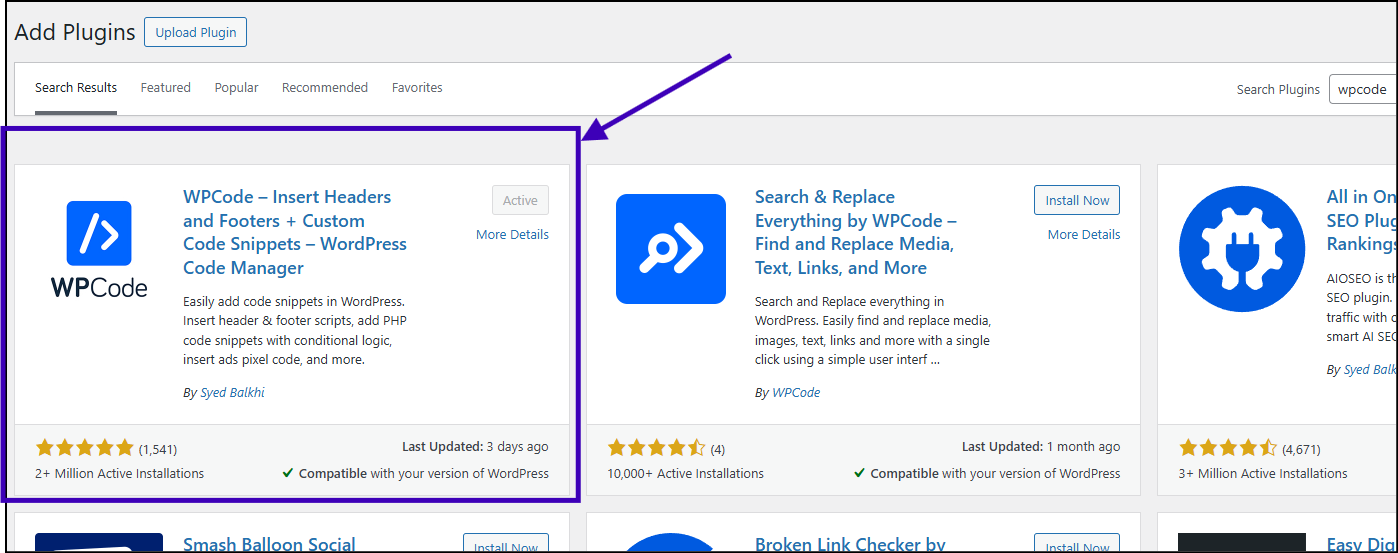
For the most straightforward method, add code to function.php on your WordPress website using WPcode or a similar plugin.
Add a new PHP code snippet
After installing the plugin, click “Code Snippets” and click “+ add snippet”. It will ask you which type of snippet you want to add, and you should select PHP snippet.
Add the PHP code
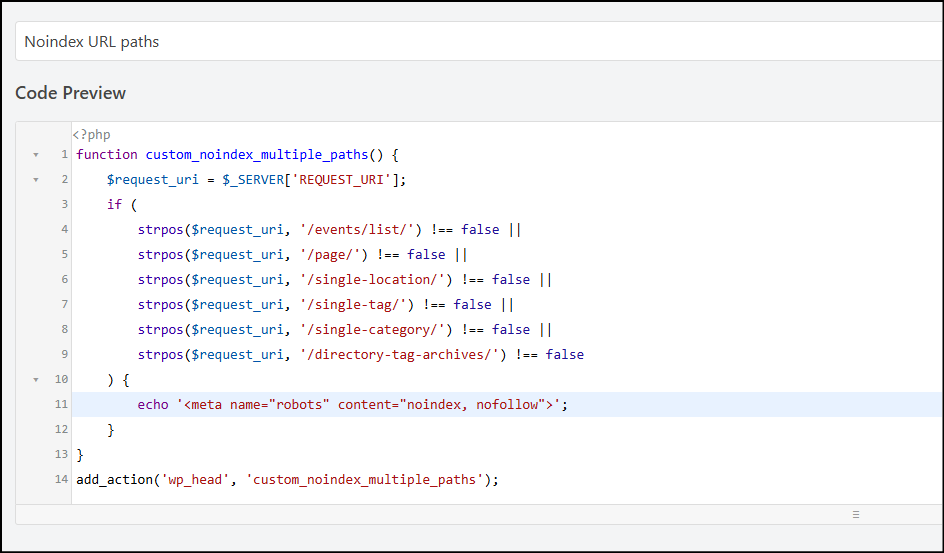
Create a new php snippet using WPCode, and add the following code to the snippet:
// start of code
function custom_noindex_multiple_paths() {
$request_uri = $_SERVER[‘REQUEST_URI’];
if (
strpos($request_uri, ‘/your-url-path/‘) !== false ||
strpos($request_uri, ‘/more-url/block/‘) !== false ||
strpos($request_uri, ‘/directory/list-view‘) !== false
) {
echo ‘<meta name=”robots” content=”noindex, nofollow”>’;
}
}
add_action(‘wp_head’, ‘custom_noindex_multiple_paths’);
// end of code
Add the URL paths you want to noindex and nofollow by replacing /your-url-path/, /more-url/block/ and /directory/list-view in the code above. Remember, the last line should not contain “||”.
Save the snippet and Run Everywhere
In the place where you can set the location, you can set it as run everywhere.
Enable your Script
Remember to enable your script after saving, and make sure the snippet is set to PHP snippet.
How Do You Verify Your Implementation?
Now that you’ve blocked specific URL paths on Google Search, you should check whether your implementation is correct.
How Does A Robots Meta Tag Look When a Page is Set to “noindexed”
Consider this URL, which is generated dynamically when the links are crawled on the source page.
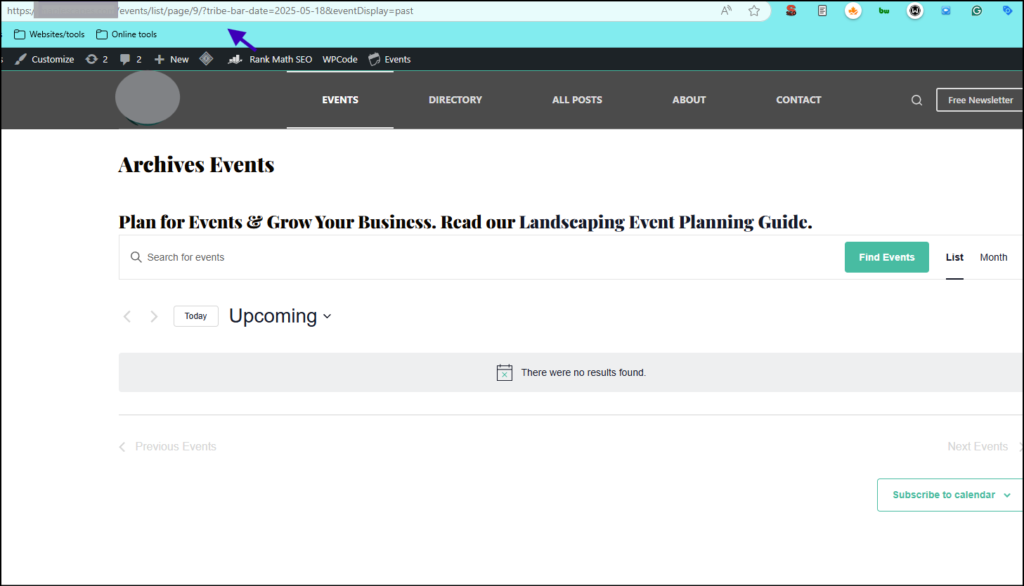
This page is the very definition of thin content – and search engines are crawling it.
https://example.com/events/list/page/9/?tribe-bar-date=2025-05-18&eventDisplay=pastBecause of your implementation, this page is set to noindex and nofollow; you should be able to see it using Chrome DevTools.
To check the robots meta tag, right-click anywhere on this page and select inspect.
Under the elements tab, press “Ctrl + F” or “cmd + F”, and type “noindex”
Now you should be able to see the robots meta tag implemented:
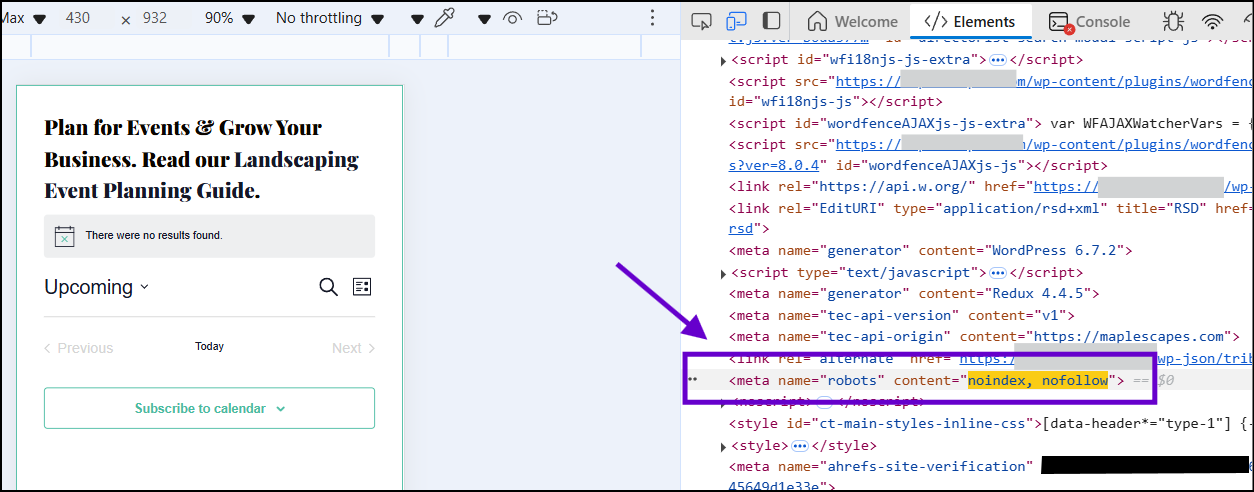
Search engines, while crawling this URL, should respect the Robots Meta directive and ignore this page while indexing other pages on this website.
Check your implementation using Google Search Console
The Google search console lets you check a live URL and show the crawl status of that page.
Select a URL that you don’t want indexed. After you’ve implemented the above steps, you can use the URL inspection tool to live test the URL.
To do this, go to your Google Search Console property, use the URL inspection tool from the top, enter your URL, and hit enter on your keyboard.
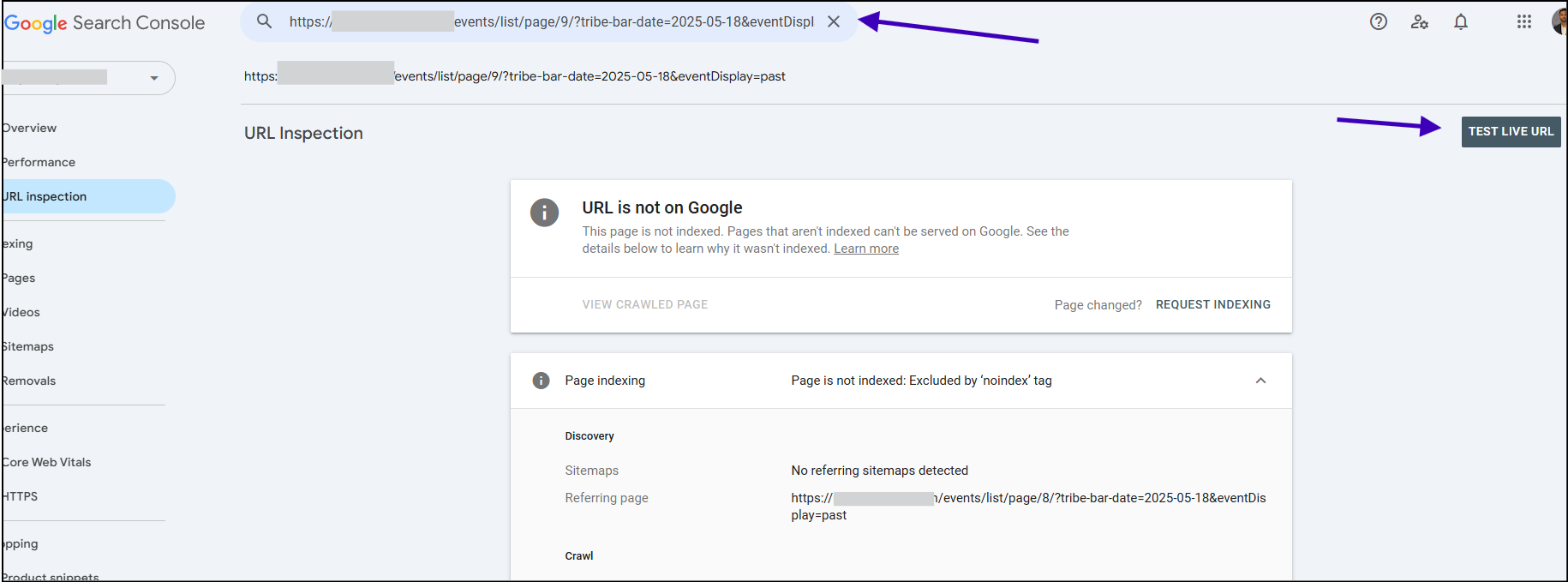
On the top right, you’ll see a button – click on “TEST LIVE URL”.
After a few seconds, you’ll see the live results.
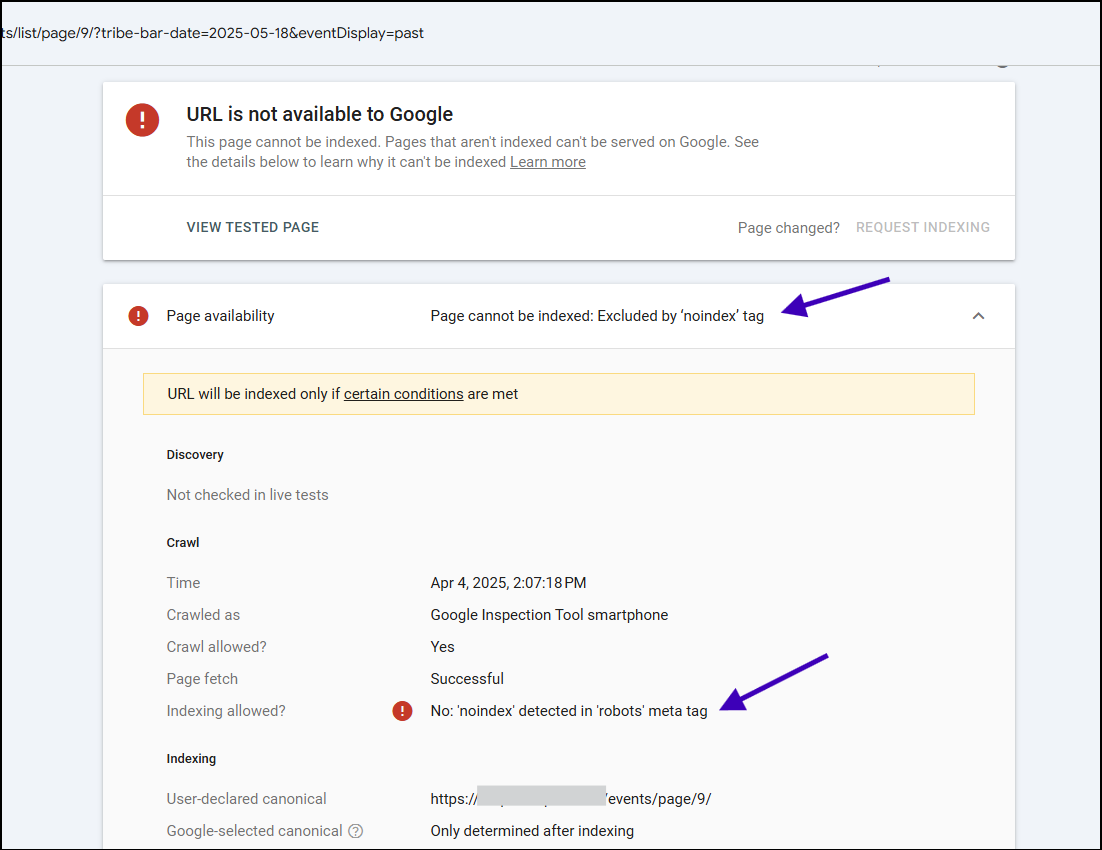
Note that there is a basic but essential difference between fetching page status with the URL inspection tool and the Live URL test.
The initial results show the status of the Google index (historic), while the live one shows the live test.
For our purpose, always check the live status to see if your implementation of noindex robots meta is correct.
Check your implementation using a third-party tool
If you cannot access Google Search Console, you can always see the robots meta using the Chrome DevTools Elements tab.
Alternatively, you can use a third-party website to check robots implementation quickly.
You can search Google for “noindex tag test online” or something similar to find a website that allows you to enter the URL and see the results.
I’ve used “https://www.siteguru.co/free-seo-tools/noindex” to show you how simple it is:
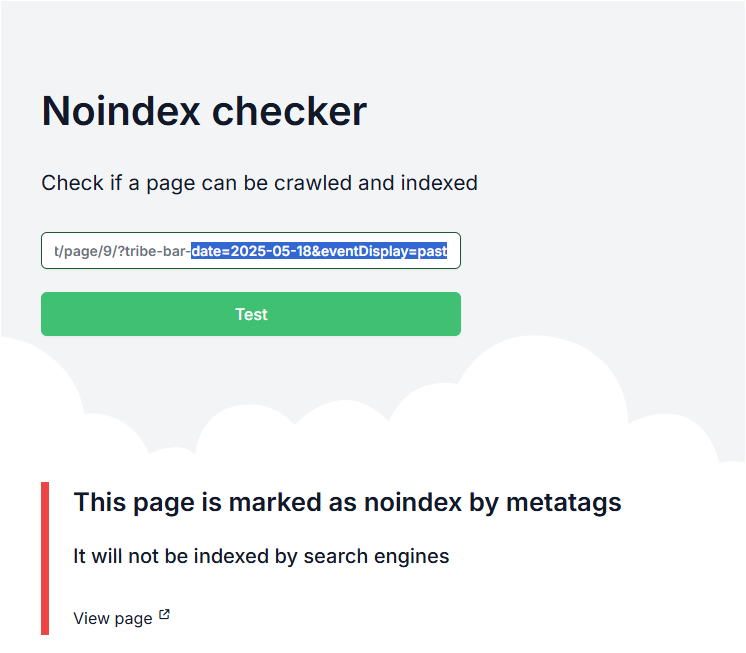
Inquisitive?
The problem that led to this solution
I realized I had to noindex some URL paths while doing a page indexing checkup in Google Search Console.
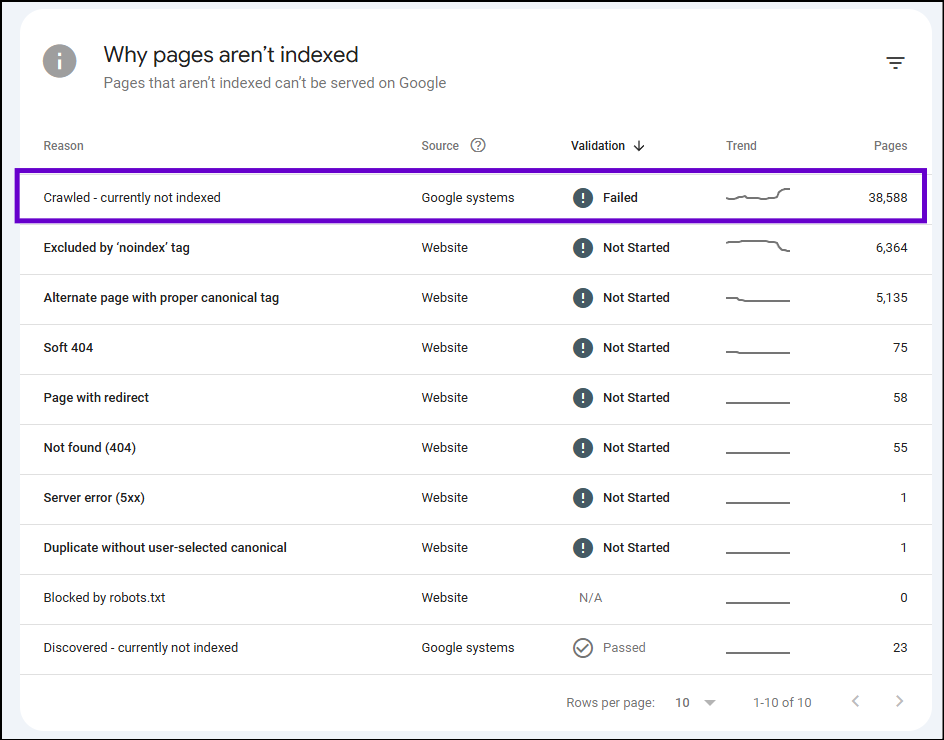
We know that Google can determine which pages shouldn’t be indexed. I wondered if it had already indexed any irrelevant pages. (Because no system is perfect!)
So I checked the indexed pages and reviewed if they have any clicks or impressions.
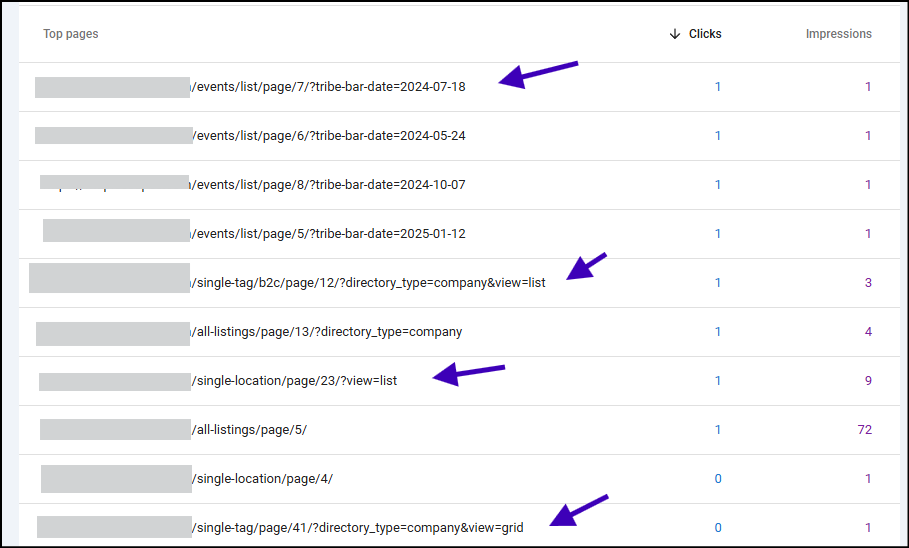
And there it is: many pages I don’t intend to index appear on Google search.
Now I know what WordPress plugins are causing these—a directory and an events plugin. However, there are limited options to control the meta robots for these URL types in search. My SEO plugin can’t control the Meta Robots tags for these urls.
So, I exported all these URLs from Google Search Console, identified a pattern, and decided that these URL paths had to be explicitly no-index.
The URL Paths that I found and ultimately set to no-index:
- /events/list/
- /single-location/
- /single-tag/
- /single-category/
- /directory-tag-archives/
Why is this a problem?
Below are some of the things that I considered before deciding to block these URLs:
- These URLs aren’t crawler-friendly.
- Because of how these plugins work, each link on these pages takes the user/crawler to a different page with some content generated by the plugin.
- For example, each date in a calendar would have a page, even though no event is scheduled for that date.
- Though there is some value for the users exploring the site,
- It’s an issue for crawlers because many would give up just trying to crawl every link on every URL.
- There are thousands of URLs, and because no algorithm is perfect,
- It might dilute PageRank, or many pages with thin content might risk getting negatively marked by helpful content classifiers.
- Some pages are being indexed,
- They’re neither helpful for the users nor visitors from Google search.
- They’re being ranked because of dynamically injected content, which is causing duplication issues on the URLs with similar content.
- Crawling these URLs wastes Google’s and other crawler resources.
- If you have a large site, this might negatively impact your crawl budget.
- You’d want to isolate these pages on your website to help search engines understand your helpful content for the users.
- Another primary reason for me was that some critical pages were in this mix, which were also not indexed.
- Because thousands of these irrelevant pages plagued my reports, I couldn’t clearly see the important ones being slipped into the “crawled not indexed” or “discovered not indexed pages” report.
Code explanation
function custom_noindex_multiple_paths() {
$request_uri = $_SERVER['REQUEST_URI'];
if (
strpos($request_uri, '/events/list/') !== false ||
strpos($request_uri, '/single-location/') !== false ||
strpos($request_uri, '/single-tag/') !== false ||
strpos($request_uri, '/single-category/') !== false ||
strpos($request_uri, '/directory-tag-archives/') !== false
) {
echo '<meta name="robots" content="noindex, nofollow">';
}
}
add_action('wp_head', 'custom_noindex_multiple_paths');This code tells WordPress to automatically add a Robots Meta Tag to the header of specific pages.
This Robots Meta Tag tells search engines:
- Don’t show this page in search results.
- Don’t follow any of the links on this page.
The pages that get this tag contain URLs with specific patterns, such as those for event lists, pagination, single locations, tags, categories, or directory tag archives. This is a way to prevent those types of pages from being indexed by search engines.
function custom_noindex_multiple_paths() { ... }defines a function.$request_uri = $_SERVER['REQUEST_URI'];retrieves the URL of the current web page being visited. It’s like the code asking the server, “What page are we on?”. The URL is stored in the$request_urivariable.- The
ifstatement checks if the current URL ($request_uri) contains any of the following strings:/events/list//single-location//single-tag//single-category//directory-tag-archives/
- The
strpos()function checks if one string exists within another. The!== falsepart means “if the string is found.” The||symbols mean “OR,” so the condition is TRUE if any of those strings are found in the URL. - If the
ifcondition is TRUE (meaning the URL matches one of the patterns), the following line is executed:echo '<meta name="robots" content="noindex, nofollow">';
- This line adds an HTML
<meta>tag to the<head>section of the web page. add_action('wp_head', 'custom_noindex_multiple_paths');– This line tells WordPress to execute thecustom_noindex_multiple_paths()function.'wp_head'refers to the<head>section of every page on your WordPress site.- So, this line says: Whenever WordPress is generating the
<head>section of a page, also run mycustom_noindex_multiple_paths()function.
FAQs
How do you check if a page’s Robots Meta Tag is set to noindex?
Three ways – third-party website, Chrome dev tools, GSC live URL test.
Why not use Robots.txt to block these URLs?
robots.txt prevents crawling, not necessarily indexing.
The Disallow directive in robots.txt tells search engine bots not to access specific URLs. If a page is disallowed in robots.txt, search engines ideally won’t crawl it. However, if that URL is linked to other websites, Google might still index it based on those external links, even without crawling the page directly. They might show a result with limited information.
Why not use canonicalization?
Canonicalization is another solution for this type of problem. But I don’t want crawlers wasting resources on URLs only generated for users on an ad-hoc basis. As new content is added to that website regularly, the content for a few thousand pages would change when the crawl starts to crawl one URL. This solution would help save the crawl budget.
References
- https://chrisleverseo.com/forum/t/deploy-noindex-meta-tag-using-if-statement-php.20/
- https://chrisleverseo.com/forum/t/deploying-noindex-meta-robots-tag-with-javascript-with-tag-manager-2-methods.90/
- https://stackoverflow.com/questions/57937319/how-do-i-add-a-noindex-nofollow-metatag-to-specific-wordpress-pages
- https://whitewp.com/wordpress-noindex/