
Know the potential reasons for no page description. If you want to know how to fix no information is available on this page; look at the solutions mentioned under each prominent reason for this message.
What is a page description, and why do search engines show it?
Search engines show a title and a page description of the content inside a page to help visitors determine the results that satisfy their search intent.
This is often accompanied by other information such as review stars, site links, images, etc. However, the title and description are the definitive factors determining whether a person wants to click on the link.

Search engines like Google organize the information they get by crawling content on the web and delivering the most relevant ones to their visitors.
They show descriptions (Snippets) of each page and its title so that users can determine what the page is about and whether it is relevant to their search.
Website owners generally indicate this description to search engines by placing a “meta description tag” on the page.
Search engines consider this tag and show it to users if it is relevant to them.
Sometimes, search engines create the description themselves if they think it would be more helpful to the user to show a different one.
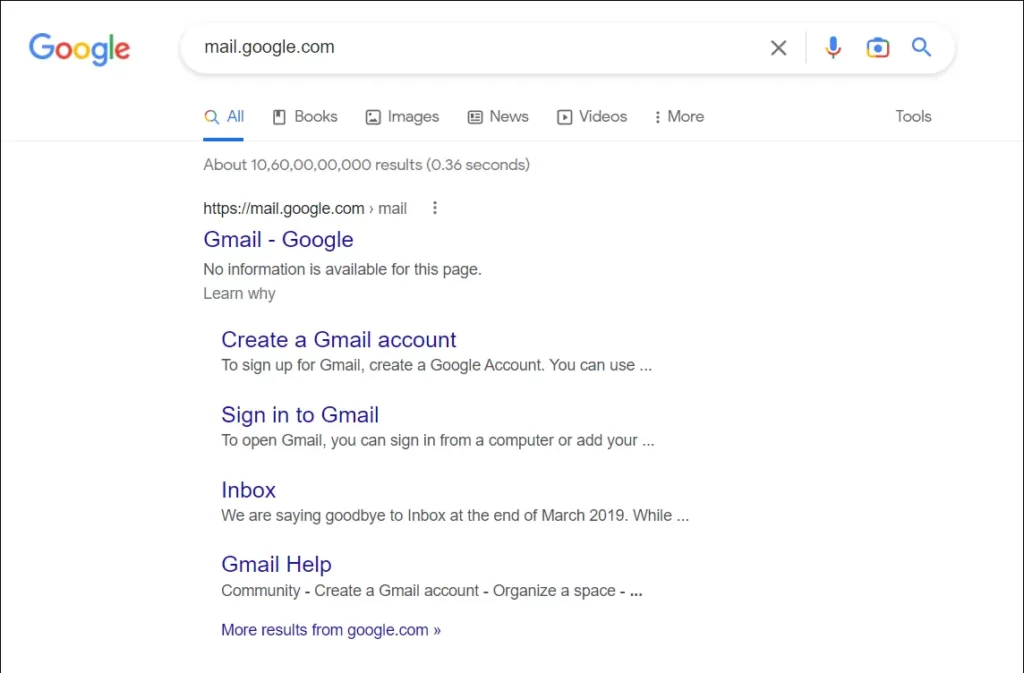
Why isn’t there a page description on Google search results?
The most prominent reasons for “No information is available for this page” are:
- The webpage is blocked to crawlers in the robots.txt file but is allowed to index.
- Meta Robots “
nosnippet” tag is present or “maxsnippet” tag is set to 0 for the page. - The domain is part of a redirect chain
- The robots.txt file is NOT present/accessible to crawlers.
I’ll expand on each of the reasons below.
1. The page is blocked in the robots.txt file but is allowed to be indexed.
To understand this reason for no page description, you need to know what is:
- robots.txt
No Indexrobots meta tag orX-Robots-Tagin an HTTP response header- difference between crawling and indexing.
Explanation/What are you talking about?
Robots.txt contains requests to crawlers that they should crawl/not crawl a particular path/link.
Google uses the robots.txt file to understand where crawlers are allowed and where they aren’t. It also uses this file to create page descriptions. If a page is not allowed to be crawled, the crawlers will not fetch the meta descriptions and certain other things.
Meta robots – Noindex tag (or noindex directive in an X-Robots-Tag HTTP header directive )tells search engines not to index a particular page for search results.
According to Google, Page description information has very much to do with Robots.txt file and noindex tag.
When a page is blocked to crawlers as specified in the Robots.txt file and allowed to be indexed normally, the search engine results page shows the message “no information is available on this page. Learn why” instead of the page description.
This is because –
- Crawlers could not fetch the page description because it was blocked in the robots.txt file.
- Since the page can be indexed, it appears on the search results page along with just the title.
Even if you have asked the crawlers not to crawl a particular page, the webpage might be discoverable through other links. If the page is set to index, the crawlers will still index the page to show it to relevant users. However, since the robots.txt file blocked the crawler from a particular directory/subdirectory and the page, the crawler’s functions (creating/reading the page description) were not completed.
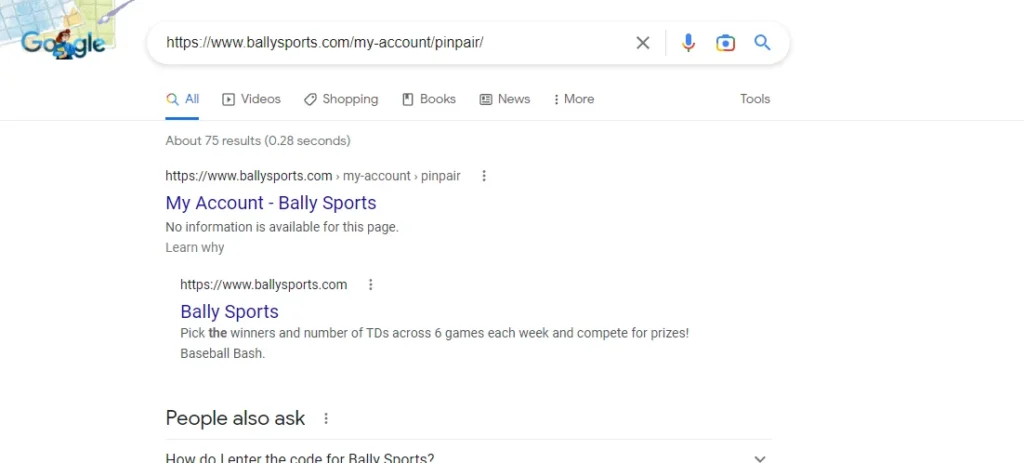
Analyzing the issue using an Example
So, this Bally Sports URL on the SERP does not show the page description.
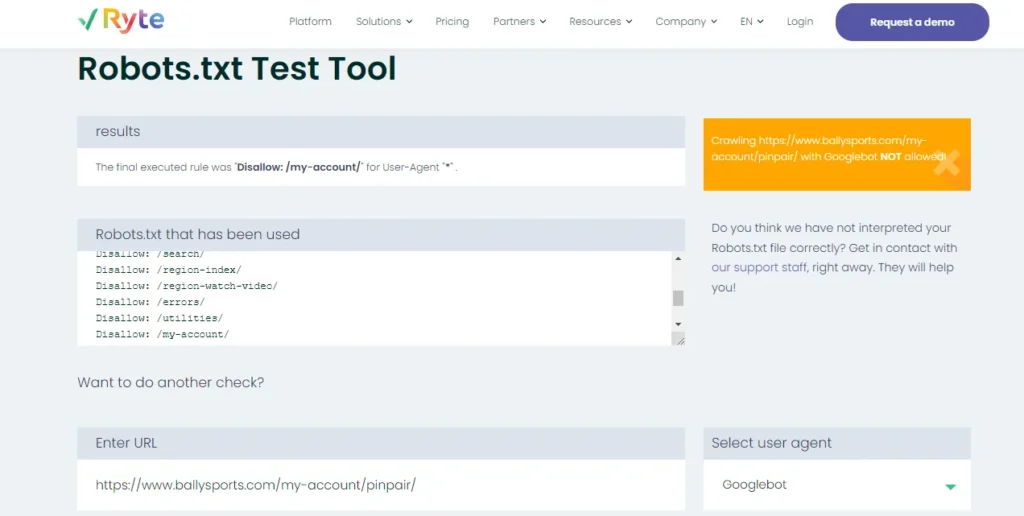
When you check the same URL using a robots.txt testing tool, you find a particular subdirectory disallowed in the file.
When you inspect the robots.txt file of the domain, you will find that the /my-account/ path has been disallowed. This could have been because the pages in this path are- irrelevant to search, behind a login wall, behind a paywall, or for managing the crawl budget of the site, etc.
The actual URL is allowed to be indexed. It is not blocked with a noindex meta robots tag or an HTTP header directive.
To verify the indexability, you can use noindex tag test online. Here are the results from when I checked:
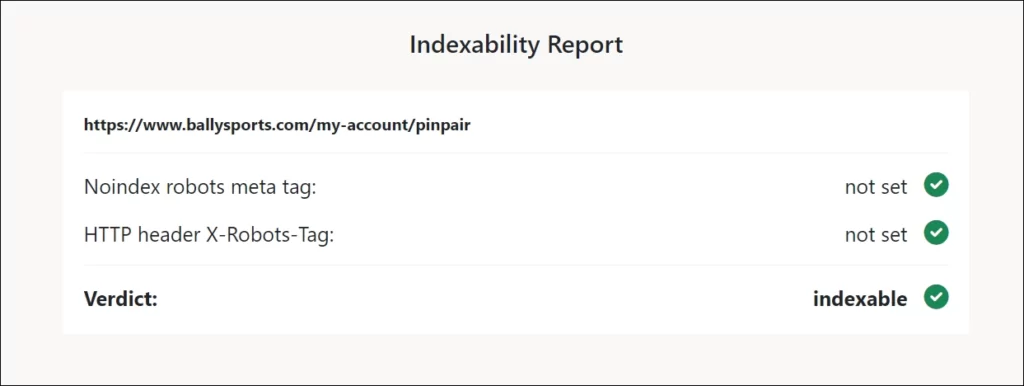
The webmaster may have a pretty good explanation for keeping it indexed. It could be because there is another URL that is distributed and known everywhere else, and this distributed URL redirects to the URL we are analyzing.
Another reason could be that the other URL is first used to check if the user has been logged in or for better integration of physical devices and online services.
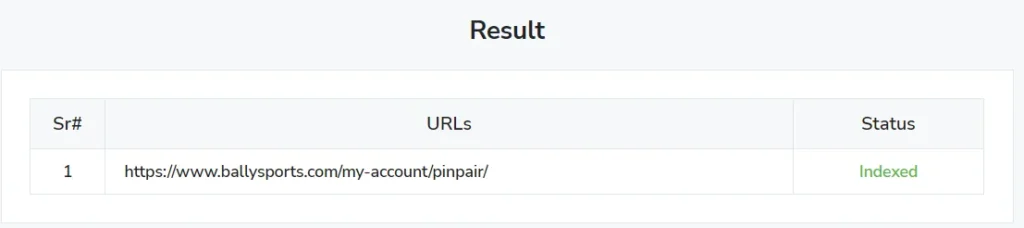
Solution for fixing: No information is available for this page:
If you are wondering how to Let Search Engines Show the Meta Description of your Page, here is the solution:
If a particular path on your site is disallowed for crawling, the solution is to ensure that the parameters mentioned in the robots.txt file do not block your subject URL.
For example, you can read this answer on Stack Exchange. “Stephen Ostermiller” asked this question, and he specified a parameter in the robots.txt file for not indexing specific URLs. His subject URL (for which he saw no page description on search) was not explicitly disallowed in robots.txt file. But the URL was still falling under that parameter/rule set.
2. Meta Robots nosnippet tag is present or maxsnippet tag is set to 0 for the page.
Meta robots tag instructs crawlers on how to crawl or serve your page.
Explanation/What are you talking about?
Apart from directing crawlers for indexation, Meta Robots tags have other rules that help site owners control the serving of snippets/descriptions of the page in the search results.
You have much greater control over what content of your webpage should appear on a search results page. You can direct Google not to show any media, translations, or search box on SERP. Additionally, you can ask Google to limit the number of characters for a page description or NOT show a page description.
The relevant tags are:
<meta name="robots" content="nosnippet">
<meta name="robots" content="max-snippet:0">
<div data-nosnippet>a lot of text on page</div> -----HTML attribute in bodyTo check for these tags on your page, you can inspect them using the Chrome or Edge console and then search for them, or you can view the page’s source and find them.
If these tags are present on a webpage, you’ve asked the search engine not to show any snippet/text description of the page on the search results. Resulting in visitors seeing the message.
Solution for fixing: No information is available for this page:
Search engines may automatically pick up the relevant text as a description for a specific user query, even though you have designated a meta description for that page. These directives are usually helpful when you do not want certain parts of the text to be shown as your page description or limit the description to certain characters.
- Remove the
nosnippetormax-snippetrule from the header. - If you want to control the number of characters for the page description, You can put in a number in place of X along with
max-snippet[X]rule.
3. Domain is part of a redirect chain
If a domain is part of a redirect chain, the destination URL title and description are usually shown when it is searched on Google.
This is only true when the final URL in the chain is whitelisted in robots.txt. If the final URL to which it is redirected is blocked in the robots.txt file, you will not see any page description in the search results.
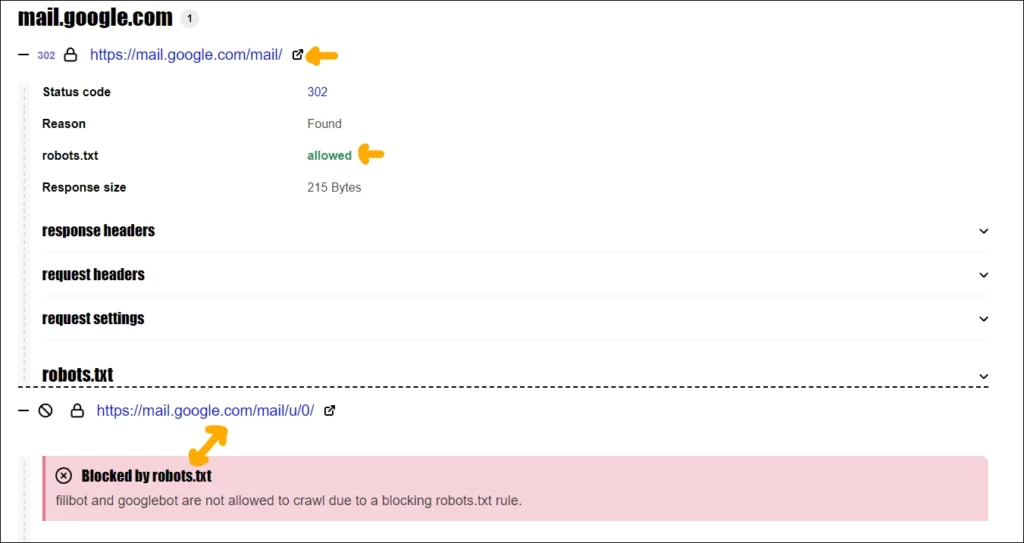
To investigate this issue, you can use a redirect checker tool. This can tell you more about the redirect chain. Sometimes, you can also look at the HTTP header response and identify if the URLs in the chain have noindex X-Robots-Tag directive.
The solution?
- Remove the X robots Tag
noindexHTTP header directive. - Ensure the chain is not too long or running in a loop so that crawlers can reach the destination page and fetch the descriptions.
4. Robots.txt file is NOT present/accessible to crawlers.
Even though a robots.txt file is made to specifically block crawlers from accessing certain parts of the site, the non-availability of the file does not generally stop crawlers from accessing page descriptions. But if there is no robots.txt file, certain pages on your site may not be crawled.
Prominent issues related to robots.txt are:
- The robots.txt file is not available
- The hosting provider is blocking Googlebots from accessing specific files, including robots.txt
- Because of some Server rules, Googlebot sees a different robots.txt file than you can see in your browser.
The Solution
Check your robots.txt file in your site’s root directory. You can create it using a free online tool if it’s not there. Use the URL inspection tool to request the URL for indexing.
Then, let search engine crawlers crawl your site again. The description will start appearing sometime.
I have made the changes; I still see no site description. What do I do?
If you have made the required changes, please wait for some time. Depending on the crawl requests and frequency of crawlers coming to your site, this information update might take some time. Once the URLs are crawled, you will see the change reflected in Search Results.
In some cases, you may have set the page for “noindex” The page still appears in search results with a description of “No information is available for this page. Learn Why”.
In this case, you may have set a meta robots tag to “noindex” At the same time, you may have disallowed the crawler from crawling that page/path etch in robots.txt. This happens because you have not allowed crawlers to read the robot directive.
The solution is to let search engines crawl that page (allow that page/directory in robots.txt) and THEN let the page be set to “noindex”. When crawler bots read the “noindex” directive on the next crawl, you will not see the page in the search results page.
Other fixes
Want to Hide the Page Description on Search Results?
So, you want to show the message that confuses people: “No information is available for this page.”
Whatever your case may be, using the meta robot tags is the easiest way. Using “Nosnippet” or “maxsnippet[0]” will work fine for this purpose.
Notes
Make sure to check these for noindex tag:
- SEO plugin settings for noindex tags (global or for a particular post) if you have a CMS like WordPress.
- Meta robot tags on pages
- X robots tag in HTTP header directives
Inquisitive?
How does this appear on Bing?
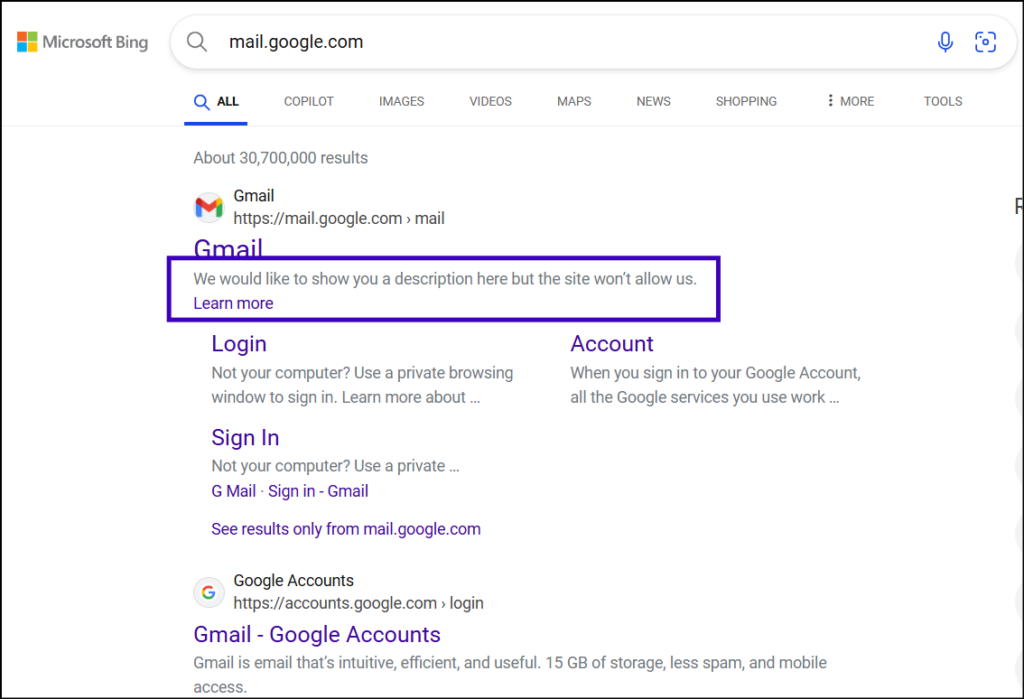
On Bing, when you view a page like on their search results, you’ll see something similar to Google.
The meta description for a similar site on Bing would say:
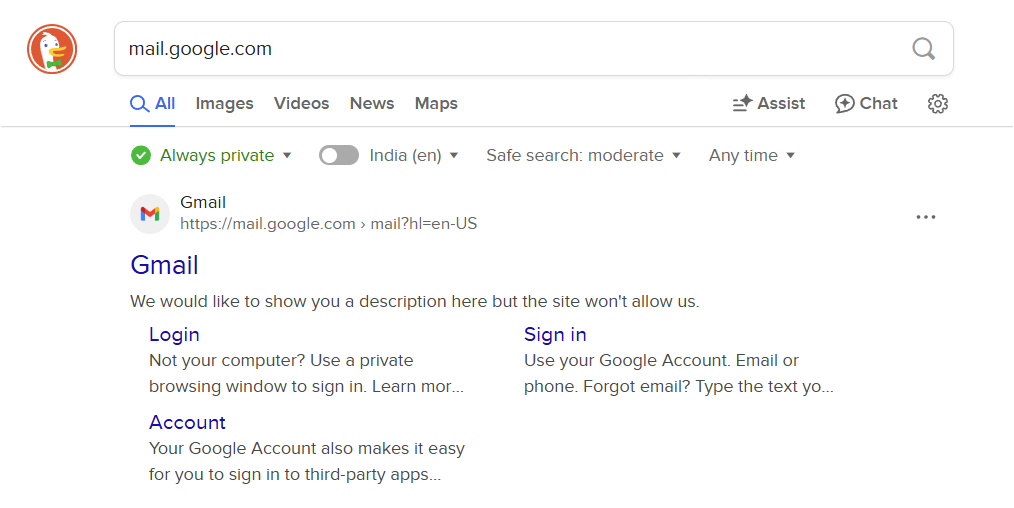
“We would like to show you a description here but the site won’t allow us.
Learn more“
Duckduckgo is a similar story. The difference is that they don’t have an explanation page dedicated to this:
Further Reading
- Google’s Interpretation of Robots.txt file. Useful for knowing how rules are read by crawlers (based on RFC 9309, Robots Exclusion Protocol).
- Use of Robots meta tag, data-nosnippet, and X-Robots-Tag for indexing.
- Yoast’s post on Robot’s meta tags and how to use them.
Off Topic: Weigh in your opinion on Dark Patterns & SEO.
Let me know your particular case and how you plan to resolve it!




works of art.